Извиняюсь за длительную паузу, времени как всегда не хватает. Спасибо за скрипт упаковщика, который вы мне прислали в ЛС. Я поставил ряд экспериментов с вашим способом упаковки файлов и готов огласить результат - предложенный вами способ в корне не верен. Собирая таким образом файл client_local_English.dat вы никогда не получите рабочий файл. При таком способе записи у вас нарушается адресация внутри файла client_local_English.dat, а поскольку данный файл не имеет таблицы-словаря, то каждый из упакованных в него файлов должен иметь статический адрес. Клиент, обращаясь к файлу client_local_English.dat ищет файл точно по указанному адресу и потому смещение недопустимо.
Немного раскинув мозгами и потратив пару часов я пришел к такому решению - файл client_local_English.dat нужно не собирать с нуля, а патчить. Вот код скрипта, который из оригинального файла client_local_English.dat на выходе дает пропатченный вашими модифицированными файлами, готовый к употреблению файл локализации.
Код скрипта (+/-)
Код:
import os
dir = 'H:\Lotro_Packer\data\\en'
dir2 = 'H:\Lotro_Packer\data\\11'
from os import listdir
from os.path import isfile
from os.path import join as joinpath
with open('client_local_English_orig.dat', 'rb') as fin:
sourcedata = fin.read()
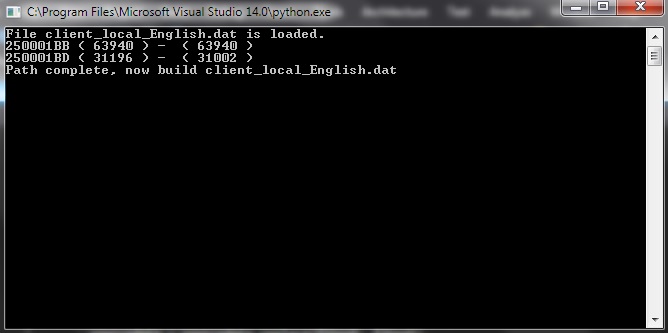
print('File client_local_English.dat is loaded.')
for file in listdir(dir2):
if isfile(joinpath(dir2,file)):
f1 = open(dir+'\\'+file, 'rb')
f1text = f1.read()
f1.close()
f2 = open(dir2+'\\'+file, 'rb')
f2text = f2.read()
f2.close()
sourcedata = sourcedata.replace(f1text, f2text)
print (file[0:8],'(',os.path.getsize(dir+'\\'+file),') - ','(',os.path.getsize(dir2+'\\'+file),')' )
print('Path complete, now build client_local_English.dat')
f3 = open('client_local_English.dat', 'wb')
f3.write(sourcedata)
f3.close()
print('Packed complete.')
dir - папка с оригинальными файлами из client_local_English.dat, нужна исключительно для проверки размера файлов
dir2 - папка с модифицированными файлами
client_local_English_orig.dat - переименованный оригинальный файл локализации
client_local_English.dat - результат работы скрипта
1. Разбираем файл client_local_RU.dat при помощи программки
DAT_UNPACKER, в результате получаем кучу папок с файлами ogg, bin, jpg и т.д.
2. Переносим все файлы(их будет примерно 186000) в одну папку и таким образом получаем папку
dir, содержащую все файлы для сравнения размера оригинальных файлов с пропатченными. Почему это важно я расскажу ниже. Путь к ней указываем в скрипте.
3. Создаем папку(
dir2), в которую кладем наши модифицированные файлы. Это основная рабочая папка, в которую мы будем складывать все, что хотим записать в файл client_local_English.dat. Указываем в скрипте путь в ней.
4. Копируем из папки с игрой в папку со скриптом файл client_local_English.dat и переименовываем его в client_local_English_orig.dat, этот файл будет использован в качестве шаблона для создания выходного файла
5. Запускаем скрипт, ждем пока он отработает и забираем из папки со скриптом готовый файл client_local_English.dat
Как я уже говорил выше, файл client_local_English.dat не имеет индексной таблицы и первые байты каждого файла, записанного в него, должны находиться строго по указанному адресу. При разборке программой DAT_UNPACKER начальный адрес соответствует названию файла. Поскольку между файлами внутри client_local_English.dat нет промежутков, то в процессе модификации важно добиться того, чтобы размер модифицированного файла не превышал размер исходного. В противном случае ваш модифицированный файл "залезет" на начало следующего файла, затрет его и файл client_local_English.dat станет неработоспособным. Если в процессе работы скрипта вы видите, что размер вашего файла превышает размер исходного, то можете даже не пробовать запускать игру с полученным файлом, дальше проверки файлов вас не пустят.
Порядок выполнения программы:
Что предстоит решить, чтобы добиться результата?
В русской локализации весь текст в файле client_local_RU.dat записан в кодировке UTF-16. В этом вы можете легко убедиться открыв любой файл в любом HEX-редакторе с поддержкой данной кодировки. При переконвертировании в любую другую кодировку, мы получаем файл большего размера, чем исходный. У меня не было времени ставить эксперименты, но первая попытка получить из UTF-16 текст приемлемого размера вышла комом. Если у кого есть идеи и соображения буду им очень рад.